Biography
New UiPath-SAIAv1 Exam Simulator | Accurate UiPath-SAIAv1 Test
To help you get to know the exam questions and knowledge of the UiPath-SAIAv1 practice exam successfully and smoothly, our experts just pick up the necessary and essential content in to our UiPath-SAIAv1 test guide with unequivocal content rather than trivia knowledge that exam do not test at all. To make you understand the content more efficient, our experts add charts, diagrams and examples in to UiPath-SAIAv1 Exam Questions to speed up you pace of gaining success. So these UiPath-SAIAv1 latest dumps will be a turning point in your life. And on your way to success, they can offer titanic help to make your review more relaxing and effective. Moreover, the passing certificate and all benefits coming along are not surreal dreams anymore.
| Topic |
Details |
| Topic 1 |
- UiPath Communications Mining - Model Training: This section of the exam measures skills of automation analysts and covers model training concepts in Communications Mining, explaining what defines a strong model and outlining the stages and components involved in developing one.
|
| Topic 2 |
- Integration Service: This section of the exam measures skills of automation analysts and covers the use of UiPath Integration Service, its connectors, and triggers, showing how these elements enable smooth interaction between UiPath and third-party systems.
|
| Topic 3 |
- Updates Introduced to 2023.10: This section of the exam measures skills of automation analysts and covers the most recent product updates in UiPath, including one-click classification and extraction, Generative AI features, and enhancements to validation, annotation, and workflow design.
|
| Topic 4 |
- Business Knowledge: This section of the exam measures skills of automation analysts and covers the fundamental understanding of business process automation, its value in real-world operations, and essential concepts used to identify, map, and analyze business processes.
|
| Topic 5 |
- Exception Handling: This section of the exam measures skills of RPA developers and covers structured error handling using Try Catch, Throw, Rethrow, and Retry Scope. It prepares the candidate to handle and resolve automation errors gracefully.
|
| Topic 6 |
- Variables and Arguments: This section of the exam measures skills of automation analysts and covers the creation and management of variables and arguments. It introduces key data types and explains how to apply variables and arguments across workflows to pass, store, and manipulate data.
|
| Topic 7 |
- UiPath Document Understanding Framework: This section of the exam measures skills of automation analysts and covers how to apply the Document Understanding Framework, use templates, and develop proof-of-concept components. It focuses on building workflows for document processing.
|
| Topic 8 |
- Debugging: This section of the exam measures skills of automation analysts and covers debugging within Document Understanding workflows. It explores the template’s architecture, exception handling, validation steps, and post-processing techniques that ensure accuracy and fault tolerance.
|
| Topic 9 |
- UiPath Communications Mining: This section of the exam measures skills of RPA developers and covers the application of Communications Mining in automation and analytics. It distinguishes this capability from Task Mining and Process Mining, explains the interface, and describes use cases.
|
| Topic 10 |
- Platform Knowledge: This section of the exam measures skills of RPA developers and covers the high-level purpose and use of UiPath platform components, including Studio, Robots, Orchestrator, and Integration Service. It also explains the difference between attended and unattended processes, providing foundational knowledge of process deployment environments.
|
| Topic 11 |
- Version Control Integration: This section of the exam measures skills of automation analysts and covers the use of Git integration in UiPath Studio for source control, including committing changes, cloning repositories, and pushing updates in collaborative environments.
|
| Topic 12 |
- UiPath Studio - Document Understanding Activities: This section of the exam measures skills of RPA developers and covers configuring document classification and extraction workflows using Studio activities, taxonomy management, digitization, and validation tools. It also includes the use of trained ML models and prebuilt extractors.
|
| Topic 13 |
- Control Flow: This section of the exam measures skills of RPA developers and covers debugging methods and logic handling in projects. It introduces the use of breakpoints, tracepoints, and debugging panels for managing and improving workflow execution.
|
| Topic 14 |
- Studio Interface: This section of the exam measures skills of RPA developers and covers essential navigation and setup within UiPath Studio. It includes installing Studio, connecting to Orchestrator, navigating the interface, managing packages, configuring activity settings, and publishing processes to Orchestrator.
|
| Topic 15 |
- Email Automation: This section of the exam measures skills of RPA developers and covers automating email processes using Microsoft 365 and Gmail integrations. It focuses on sending, receiving, and managing emails as part of workflow automation.
|
| Topic 16 |
- UiPath Communications Mining - Taxonomy Design: This section of the exam measures skills of RPA developers and covers how to design a taxonomy for Communications Mining, enabling models to interpret and structure data effectively during classification and automation processes.
|
| Topic 17 |
- Orchestrator: This section of the exam measures skills of RPA developers and covers Orchestrator's structure and functionality, including entities at the tenant and folder level. It includes using assets, queues, storage buckets, and provisioning robots along with setting up roles and logging.
|
| Topic 18 |
- Workflow Analyzer: This section of the exam measures skills of RPA developers and covers using Workflow Analyzer and validation tools to identify errors, maintain project compliance, and ensure workflow efficiency during development.
|
| Topic 19 |
- Data Manipulation: This section of the exam measures skills of RPA developers and covers data handling with VB.Net string functions, RegEx patterns, arrays, lists, and dictionaries. It also covers DataTable operations such as building, filtering, and converting data for automation.
|
| Topic 20 |
- Implementation Methodology: This section of the exam measures skills of automation analysts and covers project lifecycle knowledge, understanding key stages of implementation, and interpreting Process Design Documents (PDDs) and Solution Design Documents (SDDs).
|
| Topic 21 |
- UiPath AI Center: This section of the exam measures skills of automation analysts and covers the basics of UiPath AI Center, its role in applying machine learning to automation, and the industries where AI models can be applied effectively.
|
| Topic 22 |
- UiPath Document Understanding: This section of the exam measures skills of RPA developers and covers the concepts and capabilities of UiPath Document Understanding, including processing various document types, understanding rule-based and ML-based extraction, and distinguishing DU from traditional OCR.
|
>> New UiPath-SAIAv1 Exam Simulator <<
Accurate UiPath-SAIAv1 Test | UiPath-SAIAv1 Latest Exam Guide
Differ as a result the UiPath-SAIAv1 questions torrent geared to the needs of the user level, cultural level is uneven, have a plenty of college students in school, have a plenty of work for workers, and even some low education level of people laid off, so in order to adapt to different level differences in users, the UiPath-SAIAv1 Exam Questions at the time of writing teaching materials with a special focus on the text information expression, so you can understand the content of the UiPath-SAIAv1 learning guide and pass the UiPath-SAIAv1 exam easily.
UiPath Specialized AI Associate Exam (2023.10) Sample Questions (Q71-Q76):
NEW QUESTION # 71
Having the following Rules defined in the Taxonomy Manager for Billing Address field.
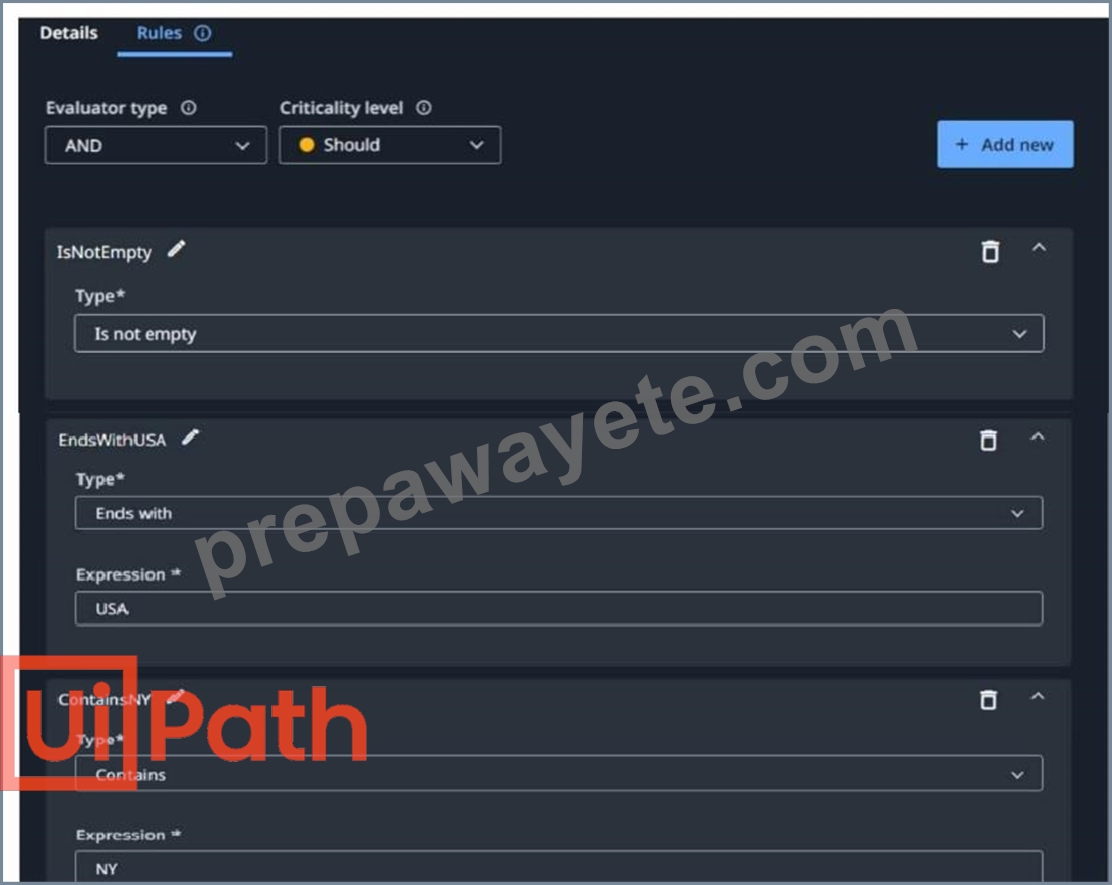
At the data extraction step. 42 W 80th St. West New York, NJ 1234, USA have been extracted (or the Billing Address field. When processing a Invoice using the DU process what will happen in (he Validation Station after data extraction step?
- A. There will be a warning message for Billing Address field regarding the ContalnsNY rule, but the validation can be performed.
- B. There will be an error for Billing Address field regarding the ContalnsNY rule, but the validation can be performed.
- C. There will be an error for Billing Address field regarding the ContainsNY rule, and the validation step will throw the user specified exception.
- D. There will be a warning message for Billing Address field regarding the ContalnsNY rule, and the validation step will throw the user specified exception.
Answer: A
Explanation:
In this scenario, the rules defined in the Taxonomy Manager are as follows:
IsNotEmpty: Ensures that the field is not empty.
EndsWithUSA: Checks if the extracted address ends with "USA".
ContainsNY: Ensures that the extracted address contains "NY".
The address extracted in this case is: "42 W 80th St. West New York, NJ 1234, USA". While the address ends with "USA" (passing the EndsWithUSA rule), it includes "West New York, NJ", which satisfies the ContainsNY rule even though "NY" is part of "New York". However, the exact behavior of the Contains rule can generate a warning message because "NY" is part of a largerstring ("New York"). Since this does not constitute an error but simply a rule conflict, the validation can proceed.
Therefore, the most accurate outcome would be a warning, but validation can still be performed
NEW QUESTION # 72
What is the difference between OCR (Optical Character Recognition) and IntelligentOCR?
- A. OCR (Optical Character Recognition) is a method that reads text from images, recognizing each character and its position, while IntelligentOCR is an enhanced version of it that can also work with noisier input data.
- B. IntelligentOCR is simply a rebranding of the OCR (Optical Character Recognition), both of them being methods that read text from images, recognizing each character and its position.
- C. IntelligentOCR is a UiPath Studio activity package that contains all the activities needed to enable information extraction, while OCR (Optical Character Recognition) is a method that reads text from images, recognizing each character and its position.
- D. OCR (Optical Character Recognition) is a UiPath Studio activity package that contains IntelligentOCR as an activity used to read text from images, recognizing each character and its position. OCR is widely used in Document Understanding processes.
Answer: C
Explanation:
According to the UiPath documentation and web search results, OCR (Optical Character Recognition) is a method that reads text from images, recognizing each character and its position. OCR is used to digitize documents and make them searchable and editable. OCR can be performed by different engines, such as Tesseract, Microsoft OCR, Microsoft Azure OCR, OmniPaqe, and Abbyy. OCR is a basic step in the Document Understanding Framework, which is a set of activities and services that enable the automation of document processing workflows.
IntelligentOCR is a UiPath Studio activity package that contains all the activities needed to enable information extraction from documents. Information extraction is the process of identifying and extracting relevant data from documents, such as fields, tables, entities, and labels. IntelligentOCR uses different components, such as classifiers, extractors, validators, and trainers, to perform information extraction.
IntelligentOCR also supports different formats, such as PDF, PNG, JPG, TIFF, and BMP. IntelligentOCR is an advanced step in the Document Understanding Framework, which builds on the OCR output and provides more functionality and flexibility.
References:
About the IntelligentOCR Activities Package
OCR Activities
OCR Feature Comparison: Uipath Community vs Uipath Licensed OCR
Document Understanding - Introduction
NEW QUESTION # 73
How is the Taxonomy component used in the Document Understanding Template?
- A. To apply rigor in the taxonomy of data, ensuring any newly discovered object fits into one and only one category or object.
- B. To organize knowledge by using a controlled vocabulary to make it easier to find related information.
- C. To define the document types and the pieces of information targeted for data extraction (fields) for each document type.
- D. To apply relationship schemas other than parent-child hierarchies, such as network structures on the processed data.
Answer: C
Explanation:
According to the UiPath documentation, the Taxonomy component is used in the Document Understanding Template to define the document types and the fields that are targeted for data extraction for each document type. The Taxonomy component is the metadata that the Document Understanding framework considers in each of its steps, such as document classification and data extraction. The Taxonomy component allows you to create, edit, import, or export the taxonomy of your project, which is a collection of document types and fields that suit your specific objectives. The Taxonomy component also allows you to configure the field types, details, and validations, as well as the supported languages and categories for your documents.
References:
Document Understanding - Taxonomy
Document Understanding - Taxonomy Overview
Document Understanding - Create and Configure Fields
NEW QUESTION # 74
What happens to your document and the process of pre-labeling when you choose the "Predict" option from the "Predict" dropdown in Document Manager?
- A. It merges the results of the Generative Predict functionality and the results of the prelabeling endpoint (if configured). If the latter is not configured, it uses solely Generative Predict for all fields.
- B. It predicts all fields using the Generative Predict capability only, ignoring any pre-labeling endpoint that may be configured. If Generative Predict is not available, it will not predict any fields.
- C. It predicts fields using the Generative Prelabeling for OOTB document types and the pre-labeling endpoint for custom document types.
- D. It predicts fields using only the prelabeling endpoint model configured in the Prelabeling settings, and it does not use Generative Predict.
Answer: A
Explanation:
Reference: UiPath Document Manager - Predict Feature
NEW QUESTION # 75
What is the page unit cost per extracted page for the RegEx Extractor?
Answer: C
Explanation:
According to the UiPath documentation, the RegEx Extractor is a data extraction method that uses regular expressions to define and capture data from documents1. The RegEx Extractor does not consume any page units, which are the units of measurement for the consumption of Document Understanding services2.
Therefore, the page unit cost per extracted page for the RegEx Extractor is 0.
References:
1: RegEx Extractor 2: Document Understanding - Metering & Charging Logic
NEW QUESTION # 76
......
The UiPath-SAIAv1 exam question offer a variety of learning modes for users to choose from, which can be used for multiple clients of computers and mobile phones to study online, as well as to print and print data for offline consolidation. For any candidate, choosing the UiPath-SAIAv1 question torrent material is the key to passing the exam. Our study materials can fully meet all your needs: Avoid wasting your time and improve your learning efficiency. Spending little hours per day within one week, you can pass the exam easily. You will don't take any risks and losses if you purchase and learn our UiPath-SAIAv1 Latest Exam Dumps, do you?
Accurate UiPath-SAIAv1 Test: https://www.prepawayete.com/UiPath/UiPath-SAIAv1-practice-exam-dumps.html
